Client vs Server Analytics
Site analytics is an important tool for web developers and stakeholders alike. Knowing where visitors are coming from, how they're interacting with your content, and why they're leaving can provide valuable information on how to better serve your audience both on- and off-line. There are several different ways to collect analytics and behavior, each with their own benefits and limitations. After several long conversations with colleagues I figured it was time to sit down and write them out.
Client-side Analytics
Using Javascript to implement a third-party tool (usually Google Analytics) is fairly standard practice. These tools have invested a lot of money and resources into building out robust reporting pieces and helpful utilities (such as the ability to pinpoint a user's location by geodata or interpreting the IP address). Implementation is easy: just plop in a few lines of Javascript and let the tool figure out the rest.
Server-side Analytics
Some web hosts have built-in tools with their server, like AWStats, that track server hits. Since they're already configured and on the server-level, triggered before the scripting language is executed, they are as reliable as your website, already setup, and low maintenance. The analytics stay on the server, though, and their interface and features are limited by what the hosting company provides.
Already there are some differences in how these two work - one is executed on the client and communicates off-site and the other is executed on the server side and stays on-site. To understand more we'll need to look at the repercussions of these paths, both in terms of features and possible failure cases.
Client Communication Model
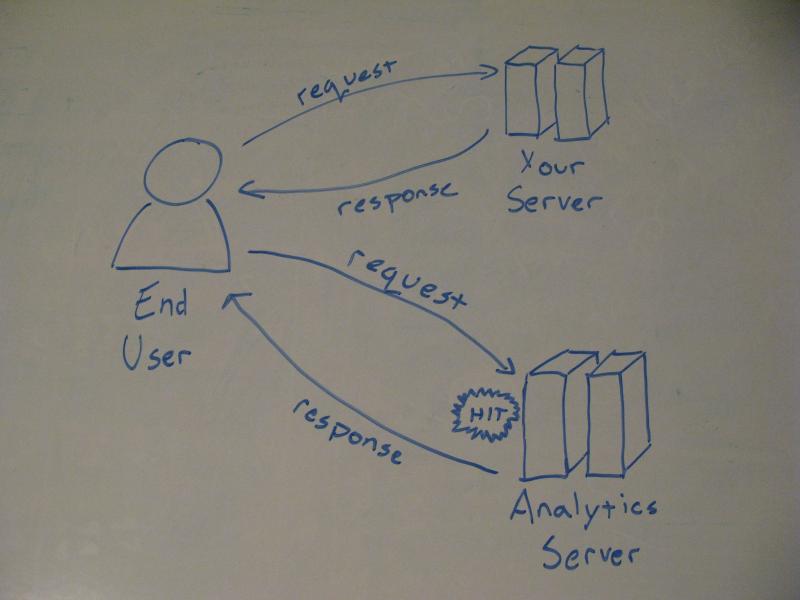
Client-side analytics communication
Once the main website has responded to a client request and the client has rendered the final page a secondary trigger is called that sends information to and from th analytics server. If the client does not enable this communication (blocks Javascript), or if the language errors out, or if they navigate away from the page before this call is completed this hit will not be captured by the analytics server. Also, the extra code, extra server call and response may add up against the overall performance of the site.
There are plenty of benefits with keeping things client-side, though. Onload, or a page hit, is just one possible trigger. With most tools out there you can capture additional events, like mouse clicks, key presses, even mouse movement (which somewhat relates to what areas draw the user's attention). Some even will process form entries, a side that is getting into sticky privacy issues, as the form data is being sent to both the analytics server (possibly non-encrypted) and the site server.
Server Communication Model
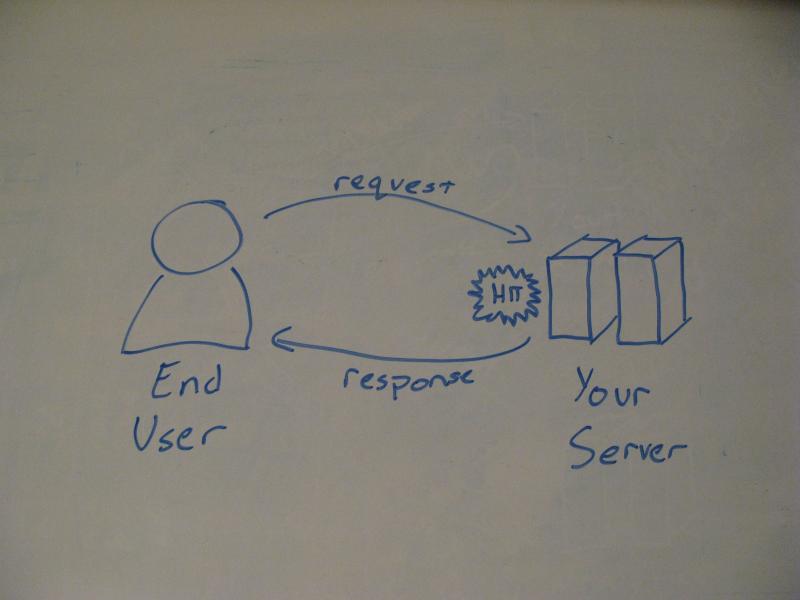
Server-side analytics diagram
Typical server analytics capture the raw request, the initial information sent from the user. That's it. If the server is capable of returning a response (so, the server is live) then the hit is captured. There is no leaning against a third-party analytics server, no depending on the user's capabilities, it just captures the request, regardless if it is a normal web page or image asset, and stores it in a log.
This allows you to capture more than just page hits by human users, too. There are hundreds of bots out there, crawling and indexing the web, and they send out requests just like actual users. They (usually) do not execute Javascript. So, server-side analytics would be captured while client-side would miss this traffic.
The downsides of server communication show up with wanting to track more detailed information, information that can only be captured as the user interacts with the page. Since the server only responds once (there usually is not a persistent connection between the user and the server) that page hit is all that comes across. Also, most server-side reporting tools are limited compared to the lavish options that third-party, centralized analytics tools offer.
So, what's the preferred method? A combination is always best. Keep the client-side analytics for tracking user behavior and provide stakeholders with pretty reporting interfaces while using the server-side analytics for internal checks and comprehensive statistics. In an ideal world you could set up a rich client-side library that would report back to your own server, enhancing server-side statistics without hitting an independent analytics server… But most projects don't need this level.
Comments (0)